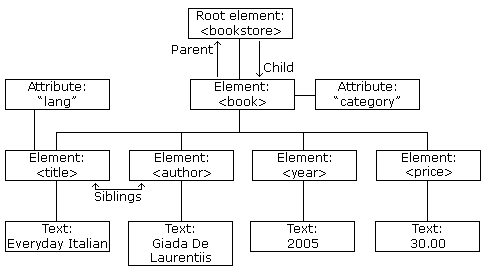
1. Extract
Syntax : extract (xmltype, xpath)
Example:
select empxml,extract(empxml,'/ROWSET/ROW[empNo="2" and dept="10"]')
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
select empxml,extract(empxml,'/ROWSET/ROW/empNo')
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
2. EXISTSNODE
EXISTSNODE determines whether traversal of an XML document using a specified path results in any nodes
The return value is
NUMBER:
Syntax : extractsNode (xmltype, xpath)
- 0 if no nodes remain after applying the XPath traversal on the document
- 1 if any nodes remain
Example:
select empxml,
existsnode(empxml,'/ROWSET/ROW/ssn') ssnTag,
existsnode(empxml,'/ROWSET/ROW/dept') deptTag
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
3. DELETEXML
DELETEXML deletes the node or nodes matched by the XPath expression in the target XML.
Syntax : DELETEXML(xmltype ,xpath)
select empxml,DELETEXML(empxml,'/ROWSET/ROW/dept')
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
INSERTCHILDXML inserts a user-supplied value into the target XML at the node indicated by the XPath expressionExample:
select empxml,insertchildxml(empxml,'/ROWSET/ROW','ssn',xmltype('<ssn></ssn>'))
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
5. InsertXMLBefore
INSERTXMLBEFORE inserts a user-supplied value into the target XML before the node indicated by the XPath expression.
Example:
from
(select xmltype('<?xml version="1.0"?>
<ROWSET>
<ROW>
<empNo>1</empNo>
<ename>Kiran</ename>
<dept>10</dept>
<salary> 1000 </salary>
</ROW>
<ROW>
<empNo>2</empNo>
<ename>Vishali</ename>
<dept>10</dept>
<salary> 1500 </salary>
</ROW>
</ROWSET>
') empxml from dual);
6. XMLROOT
XMLROOT lets you create a new XML value by providing version and standalone properties in the XML root informationSyntax: XMLROOT(xmltype, Version '1.0',StandAlone [Yes/No])
Example
select
xmlroot (
xmltype('<ROWSET>
<Row>
<SampleTag>143598</SampleTag>
<SampleTag1> 13433 </SampleTag1>
</Row>
</ROWSET>'),
version '1.0',
standalone yes)
as "XMLROOT" from dual;