XML
XML stands for eXtensible Markup Language.
XML is designed to transport and store data.
XML does not DO anything. XML was created to structure, store, and transport information.
XML Documents Form a Tree Structure
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
<child>
<subchild>.....</subchild>
</child>
</root>
XML Tags are Case Sensitive
A "Well Formed" XML document has correct XML syntax.
- XML documents must have a root element
- XML elements must have a closing tag
- XML tags are case sensitive
- XML elements must be properly nested
- XML attribute values must be quoted
Sample xml:
<?xml version="1.0" encoding="UTF-16"?>
<note>
<to>kiran</to>
<from>vishali</from>
<heading>Reminder</heading>
<body>Don't forget breakfast this weekend!</body>
</note>
<to>kiran</to>
<from>vishali</from>
<heading>Reminder</heading>
<body>Don't forget breakfast this weekend!</body>
</note>
XML DOM
The XML DOM defines a standard way for accessing and manipulating XML documents.
The DOM presents an XML document as a tree-structure.
The XML DOM is a standard for how to get, change, add, or delete XML elements.
According to the DOM, everything in an XML document is a node.
The DOM says:
The entire document is a document node
Every XML element is an element node
The text in the XML elements are text nodes
Every attribute is an attribute node
Comments are comment nodes
A common error in DOM processing is to expect an element node to contain text.
However, the text of an element node is stored in a text node.
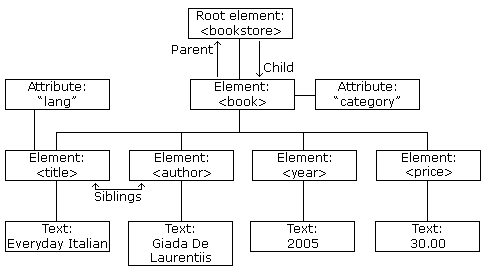
The XML DOM views an XML document as a tree-structure. The tree structure is called a node-tree.
All nodes can be accessed through the tree. Their contents can be modified or deleted, and new elements can be created.
The tree starts at the root node and branches out to the text nodes at the lowest level of the tree
The nodes in the node tree have a hierarchical relationship to each other.
The terms parent, child, and sibling are used to describe the relationships.
Parent nodes have children. Children on the same level are called siblings.
In a node tree, the top node is called the root
Every node, except the root, has exactly one parent node
A node can have any number of children
A leaf is a node with no children
Siblings are nodes with the same parent
The XML DOM contains methods (functions) to traverse XML trees, access, insert, and delete nodes.
However, before an XML document can be accessed and manipulated, it must be loaded into an XML DOM object.
The programming interface to the DOM is defined by a set standard properties and methods.
XML DOM Properties
These are some typical DOM properties:
x is a node object.
x.nodeName - the name of x
x.nodeValue - the value of x
x.parentNode - the parent node of x
x.childNodes - the child nodes of x
x.attributes - the attributes nodes of x
XML DOM Methods
x is a node object.
x.getElementsByTagName(name) - get all elements with a specified tag name
x.appendChild(node) - insert a child node to x
x.removeChild(node) - remove a child node from x
getElementsByTagName() returns all elements with a specified tag name.
The getElementsByTagName() method returns a node list. A node list is an array of nodes.
XPath
XPath is a language for finding information in an XML document.
XPath uses path expressions to select nodes or node-sets in an XML document. These path expressions look very much like the expressions you see when you work with a traditional computer file system.
Selecting Nodes
XPath uses path expressions to select nodes in an XML document. The node is selected by following a path or steps. The most useful path expressions are listed below:
| Expression | Description |
|---|---|
| nodename | Selects all nodes with the name "nodename" |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection no matter where they are |
| . | Selects the current node |
| .. | Selects the parent of the current node |
| @ | Selects attributes |
In the table below we have listed some path expressions and the result of the expressions:
| Path Expression | Result |
|---|---|
| bookstore | Selects all nodes with the name "bookstore" |
| /bookstore | Selects the root element bookstoreNote: If the path starts with a slash ( / ) it always represents an absolute path to an element! |
| bookstore/book | Selects all book elements that are children of bookstore |
| //book | Selects all book elements no matter where they are in the document |
| bookstore//book | Selects all book elements that are descendant of the bookstore element, no matter where they are under the bookstore element |
| //@lang | Selects all attributes that are named lang |
Predicates
Predicates are used to find a specific node or a node that contains a specific value.
Predicates are always embedded in square brackets.
In the table below we have listed some path expressions with predicates and the result of the expressions:
| Path Expression | Result |
|---|---|
| /bookstore/book[1] | Selects the first book element that is the child of the bookstore element.Note: IE5 and later has implemented that [0] should be the first node, but according to the W3C standard it should have been [1]!! |
| /bookstore/book[last()] | Selects the last book element that is the child of the bookstore element |
| /bookstore/book[last()-1] | Selects the last but one book element that is the child of the bookstore element |
| /bookstore/book[position()<3] | Selects the first two book elements that are children of the bookstore element |
| //title[@lang] | Selects all the title elements that have an attribute named lang |
| //title[@lang='eng'] | Selects all the title elements that have an attribute named lang with a value of 'eng' |
| /bookstore/book[price>35.00] | Selects all the book elements of the bookstore element that have a price element with a value greater than 35.00 |
| /bookstore/book[price>35.00]/title | Selects all the title elements of the book elements of the bookstore element that have a price element with a value greater than 35.00 |
Selecting Unknown Nodes
XPath wildcards can be used to select unknown XML elements.
| Wildcard | Description |
|---|---|
| * | Matches any element node |
| @* | Matches any attribute node |
| node() | Matches any node of any kind |
In the table below we have listed some path expressions and the result of the expressions:
| Path Expression | Result |
|---|---|
| /bookstore/* | Selects all the child nodes of the bookstore element |
| //* | Selects all elements in the document |
| //title[@*] | Selects all title elements which have any attribute |
Selecting Several Paths
By using the | operator in an XPath expression you can select several paths.
In the table below we have listed some path expressions and the result of the expressions:
| Path Expression | Result |
|---|---|
| //book/title | //book/price | Selects all the title AND price elements of all book elements |
| //title | //price | Selects all the title AND price elements in the document |
| /bookstore/book/title | //price | Selects all the title elements of the book element of the bookstore element AND all the price elements in the document |
No comments:
Post a Comment